


Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
細川 哲成*; 滝塚 知典
JAERI-Data/Code 2001-026, 19 Pages, 2001/10
 JAERI-Data-Code-2001-026.pdf:1.66MB
JAERI-Data-Code-2001-026.pdf:1.66MB
ダイバータ粒子コードPARASOLは、ダイバータ板に挟まれた磁場におけるプラズマの挙動を、静電PIC法と二本衝突モンテカルロ法を用いて自己無撞着に模擬する。PARASOLコードはスカラー並列計算機向きにMPI-1.1に従って並列化され、従来IntelParagonXP/Sシステムで用いられてきた。今回(2001年5月)新しくSGIOrigin3800システムが導入された。このシステムの移行に伴い、PARASOLコードの並列計算の改良を行った。新システムの高性能化とコードの改良の結果、PARASOLのシミュレーションは、前システムに比べ同数のプロセッサで約60倍高速化された。
箭竹 陽一*; 久米 悦雄; 川井 渉*; 根本 俊行*; 川崎 信夫*; 足立 将晶*; 石附 茂*; 小笠原 忍*
JAERI-Data/Code 2000-038, 57 Pages, 2000/12
JAERI-Data-Code-2000-038.pdf:2.3MB
本報告書は、平成11年度に計算科学技術推進センター情報システム管理課で行った原子力コードの高速化作業のうち、Paragonにおけるスカラ並列化作業部分について記述したものである。原子力コードの高速化作業は、平成11年度に18件行われた。これらの作業内容は、今後同種の作業を行ううえでの参考となりうるよう、作業を大別して「ベクトル/並列化編」,「スカラ並列化編」及び「移植編」の3分冊にまとめた。本報告書の「スカラ並列化編」では、高エネルギー核子・中間子輸送計算コードNMTC、ブラソフプラズマシミュレーションコードDA-VLASOV及び中性子・光子結合モンテカルロ輸送計算コードMCNP4B2を対象に実施したParagon向けのスカラ並列化作業について記述している。
金子 勇; 村松 一弘
JAERI-Data/Code 2000-020, p.16 - 0, 2000/03
JAERI-Data-Code-2000-020.pdf:0.88MB
多数のプロセッサを有する高並列計算機上においては、領域分割による数値計算手法が用いられる。ここで、解析規模の増大してきている現状では、これらの解析結果の可視化を計算本体と同時に各プロセッサで同時に行う手法が現実的なものとなりつつある。特に、リアルタイムに計算結果を可視化するという、実時間可視化を行う際には、この手法は必須のものである。そして、このような多数のプロセッサを用いて画像レンダリングを行う手法の場合、各プロセッサのレンダリング結果を最終的に一つの画像に合成する処理を行う必要があり、これは、Zバッファを用いた画像合成手法で処理が行われる。しかし、数十プロセッサを超える規模でそのZバッファ画像合成手法を行うと、処理の低速化並びに各プロセッサでのローカルメモリ不足という問題が発生する。そこで本報告では、Zバッファ画像合成処理を演算子と考え、これがReduceオペレータという特殊な演算子であることを用いた並列化手法、並びに背景情報の削除によるバッファ圧縮という、この問題に対する二つの解決法を新たに提案する。また実際に、並列計算機Paragonで評価を行った結果を示し、これらの手法の有効性を検証する。
箭竹 陽一*; 足立 将晶*; 久米 悦雄; 川井 渉*; 川崎 信夫*; 根本 俊行*; 石附 茂*; 小笠原 忍*
JAERI-Data/Code 2000-016, p.43 - 0, 2000/03
JAERI-Data-Code-2000-016.pdf:1.36MB
本研究書は、平成10年度に情報システム管理課で行った原子力コードの高速化作業のうち、Paragonにおけるスカラ並列作業部分について記述したものである。原子力コードの高速化作業は、平成10年度に12件行われた。これら作業内容は大別して「ベクトル/並列化編」、「スカラ並列化編」及び「移植編」の3分冊にまとめた。本報告書の「スカラ並列化編」では、連続エネルギー粒子輸送モンテカルロコードMCNP4B2、連続エネルギー及び多群モデルモンテカルロコードMVP/GMVP及び光量子による固体溶融蒸発シミュレーションコードPHCIPを対象に実施したParagon向けのスカラ並列化作業について記述した。
上島 豊; 荒川 拓也*; 佐々木 明; 横田 恒*
JAERI-Data/Code 99-051, p.23 - 0, 2000/01
JAERI-Data-Code-99-051.pdf:0.98MB
日本で100並列を越える並列計算が、実際に行われるようになったのは、つい数年ほど前からである。日本原子力研究所(原研)のIntel製Paragon XP/S 15GP256 那珂研究所
那珂研究所 、75MP834関西研究所は、本格的超並列計算機の先駆けとして光量子、核融合の大規模、超並列計算を目的に導入されている。これらの計算機を使って超並列計算を行うためは、多くの超並列計算プログラムが移植や新規作成されている。これらのプログラムは、従来、ワークステーションやベクトル計算機上で動作していたものをそのまま移植したものか、並列用にアルゴリズムの変更を施したものである。異なる計算機及びオペレーティングシステム(OS)のもとでのプログラム開発には、細心の注意とノウハウが必要であるが、Paragonに到ってはユーザ数が極めて少ないため、ノウハウの集積と環境の標準化が大変困難な状況にある。原研関西研究所におけるParagon XP/S 75MP834上での超並列計算プログラム開発において得た情報をParagon上でのスカラー超並列プログラム開発ガイドとしてJAERI-Data/Code 98-030にまとめた。本報告書では、超並列計算機が持つ特殊性が際立つ入出力周りにテーマを限定して、より高速かつ安定に入出力を実行できる方法をFortranとCのプログラム実例入りで解説する。
、75MP834関西研究所は、本格的超並列計算機の先駆けとして光量子、核融合の大規模、超並列計算を目的に導入されている。これらの計算機を使って超並列計算を行うためは、多くの超並列計算プログラムが移植や新規作成されている。これらのプログラムは、従来、ワークステーションやベクトル計算機上で動作していたものをそのまま移植したものか、並列用にアルゴリズムの変更を施したものである。異なる計算機及びオペレーティングシステム(OS)のもとでのプログラム開発には、細心の注意とノウハウが必要であるが、Paragonに到ってはユーザ数が極めて少ないため、ノウハウの集積と環境の標準化が大変困難な状況にある。原研関西研究所におけるParagon XP/S 75MP834上での超並列計算プログラム開発において得た情報をParagon上でのスカラー超並列プログラム開発ガイドとしてJAERI-Data/Code 98-030にまとめた。本報告書では、超並列計算機が持つ特殊性が際立つ入出力周りにテーマを限定して、より高速かつ安定に入出力を実行できる方法をFortranとCのプログラム実例入りで解説する。
上島 豊; 岸本 泰明
Proceedings of 3rd International Symposium on High Performance Computing, p.524 - 534, 2000/00
'Intel Paragon XP/S 75MP834'にチューニングしたProgressive Parallel Plasma (P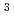 ) 2D codeを開発した。この計算機は834のノードからなり、総合性能は120GFLOPSである。それぞれのノードには1つの通信用CPUと2つの計算用CPUをもち、128MBのメモリを搭載している。この計算機の能力を十分に引き出すために、Pコードは、Variable dimension法で省メモリ・集中管理プログラミングを行い、従来の大規模計算で行っていたベクトルプログラミングをスカラプログラミングに変更することでキャッシュヒット率を向上させている。また、ノード内の2CPUを高効率で動作させるためのメモリ排他制御プログラミングや入出力を40倍以上向上させる並列入出力技法を取り入れている。この結果、53ナノ秒/粒子/ステップ(実効42GFLOPS=理論性能の35%)という、高速計算を達成した。また、計算後のデータ転送、解析処理、画面表示まで自動に制御するシステムを実装している。
) 2D codeを開発した。この計算機は834のノードからなり、総合性能は120GFLOPSである。それぞれのノードには1つの通信用CPUと2つの計算用CPUをもち、128MBのメモリを搭載している。この計算機の能力を十分に引き出すために、Pコードは、Variable dimension法で省メモリ・集中管理プログラミングを行い、従来の大規模計算で行っていたベクトルプログラミングをスカラプログラミングに変更することでキャッシュヒット率を向上させている。また、ノード内の2CPUを高効率で動作させるためのメモリ排他制御プログラミングや入出力を40倍以上向上させる並列入出力技法を取り入れている。この結果、53ナノ秒/粒子/ステップ(実効42GFLOPS=理論性能の35%)という、高速計算を達成した。また、計算後のデータ転送、解析処理、画面表示まで自動に制御するシステムを実装している。
上島 豊*; 荒川 拓也*; 佐々木 明; 横田 恒*
JAERI-Data/Code 98-030, 69 Pages, 1998/10
JAERI-Data-Code-98-030.pdf:2.07MB
ここ4,5年前までは、最も高速な計算機といえば、いわゆるスーパーコンピュータと呼ばれるベクトル型計算機であった。この型の計算機は4,5年で計算速度が10倍ずつ高速になってきた。しかし、現在、1CPUの演算速度が限界に達してきている。日本でこれを超える計算機として100並列を越える並列計算機が、実際に行われるようになったのは、つい数年前ほどからである。日本原子力研究所(原研)のIntel製Paragon XP/S 15GP256那珂研究所(那珂研)、75MP834関西研究所(関西研)は、このような計算機の先駆けとして光量子、核融合の大規模超並列計算を行う目的に導入されている。これらの計算機を使って超並列計算を行うために、多くの超並列計算プログラムが移植や新規作成されている。しかし、超並列計算機に関しては、ユーザ数が極めて少ないため、ノウハウの集積と環境の標準化が大変困難な状況にある。そのため、原研関西研究所におけるParagon XP/S 75MP834上での超並列計算プログラム開発において得た情報をParagon上での超並列プログラム開発の指針としてまとめた。
武宮 博*; 樋口 健二; 川崎 琢治*
Modeling and Simulation Based Engineering, p.497 - 502, 1998/00
粒子輸送モンテカルロコードの並列実行における動的負荷分散手法について述べる。本手法は、負荷分散実現時における通信コスト、ロードインバランスの和を最適化する点に特徴がある。本手法を粒子輸送モンテカルロコードMCNP46上に実装し、Intel Paragon上で性能評価を行った。その結果について述べる。また、他の動的負荷分散手法との性能比較結果についても述べる。
内海 隆行*; 谷 啓二
Proc. on Parallel Algorithms/Architecture Synthesis, p.200 - 205, 1997/03
微分代数的CIP法(Differential Algebraic CIP;DA-CIP)は、矢部等により提案されたCIP法をLagrange的観点から検討し直し、CIP法の非移流フェーズ計算における空間差分計算を排除し、常微分方程式の数値積分法を適用することが出来る偏微分方程式の数値解析法である。このDA-CIP法では、Burlish-Stoer法や最適積分きざみ幅制御Runge-Kutta法のように数値的に系の時定数を推定する陽的数値積分法を用いることができるため、各格子点上の状態量の時間進展計算において近接した格子点の状態量が用いられるのみである。この計算局所性より、Paragonのような超並列計算機にSPMD(Single Program Multiple Data)モデルに基づいてDA-CIP法の解析コードを作成し、VPP500と同等の結果が得られることを示した。
五來 一夫
RIST News, (24), p.9 - 20, 1997/00
日本原子力研究所のスーパーコンピュータは、東海研究所、那珂研究所、東京地区(中目黒)及び関西研究所の4サイトに合計10台設置されている。本稿では、このうちの関西研究所に平成8年3月に導入されたスーパーコンピュータ2台についてコンピュータの特徴と運用方法を紹介する。関西研究所のスーパーコンピュータは、寝屋川支所に設置され、光量子の研究開発に現在使用されている。コンピュータの特徴については、東海研究所及び那珂研究所にある類似のスーパーコンピータとの比較を含めて記述している。
折居 茂夫*; 大田 敏郎*
JAERI-Data/Code 96-023, 48 Pages, 1996/07
JAERI-Data-Code-96-023.pdf:1.52MB
分子動力学法を用いた数値シミュレーションコードの並列化を、2フェーズ法と呼ばれる並列化方法を用い、段階的に行なった。その結果、ベクトル並列計算機VPP500とスカラ並列計算機Paragonにおいて、ある計算パラメータの範囲では、doループのインデックスを使用して計算を各プロセッサに割り当てる並列化方法で並列性能を得られることがわかった。またVPP500では、広い範囲の計算でパラメータで並列性能が得られた。この理由は、doループレベルでは並列性能が出ない計算が、ベクトル化により時間コスト的に無視できるようになったためである。また、ベクトル化のためプログラムのより狭い範囲に時間コストが集中し、その部分の並列性能が出てきたためである。本報告書は、VPP500とParagonにおける分子動力学コードの段階的並列化方法とその並列性能を示す。
松山 雄次*
計算工学講演会論文集, 1(1), p.113 - 116, 1996/05
1台のCPUの高速化が限界に近づきつつある今日、より高度な演算性能を得るには、複数のCPUで並列処理を行うのが、現在一般に最も有効とされている方法である。本論文では代表的な並列計算機として、スカラ・プロセッサを採用した分散主記憶型並列システムParagon XP/S、ベクトル・プロセッサを採用した分散主記憶並列システムVPP500、同じくベクトル・プロセッサを採用した共有主記憶型マルチプロセッサ・システムMonte-4を選択した。各システムのアーキテクチャは全く異なり、並列化手段も異なっている。並列化コードとして等方乱流数値シミュレーション・コードを用い、各システムにおけるFortranパラダイムとネットワーク通信の比較等を踏まえたシステムの使用環境、FFTルーチンの並列化手法と並列最適化プログラム開発工数等、および自動並列化の機能とその結果について記述する。
岸田 則生*; 横川 三津夫; 渡辺 正; 蕪木 英雄
計算工学講演会論文集, 1(1), p.117 - 120, 1996/05
2次元Rayleigh-Benard流れに対する直接シミュレーションモンテカルロコードであるPstc-2dをIntel Paragon上で並列化した。並列化により大規模なメモリ空間が利用可能となり、今まで実行できなかったアスペクト比が8のシミュレーションを実行できた。シミュレーション結果は連続体モデルの予測結果と良く一致しており、DSMC法が連続流に近い流れの解析にも適応可能なことが判明した。並列化はParagon固有の並列化ライブラリであるNXライブラリとPVMを用いて行った。DSMC法は通信量が大きいので並列化性能はあまり良くなく、新たな並列計算向きのアルゴリズムの開発が必要なことも判明した。
武宮 博*; 太田 浩史*; 本間 一朗*
JAERI-Data/Code 96-010, 52 Pages, 1996/03
JAERI-Data-Code-96-010.pdf:2.28MB
分散メモリ型スカラ並列計算機Intel Paragon上での電磁カスケードシミュレーション用モンテカルロコードEGS4の並列化作業について述べる。EGS4コードは計算途中で動的に粒子が生成されるため、各粒子あたりの計算時間が大きく異なるという特徴を持つ。このような特徴を持つコードの高速並列実行を実現するために、並列実行単位、並列プログラミングモデル、及び並列乱数発生アルゴリズムを検討し、静的粒子割り付け手法、動的粒子割り付け手法の2手法を用いて4プログラムの並列化を試みた。その結果、3プログラムで128プロセッサ利用時に100倍程度の高速実行効率が得られた。また、本並列化作業の経験を通して、並列化作業のワークフローを分析し、並列化ツールに関する考察を行った。
大田 敏郎*
JAERI-Data/Code 96-009, 20 Pages, 1996/03
JAERI-Data-Code-96-009.pdf:0.63MB
Intel Paragon XP/Sにおけるglobal sum機能に同等で、簡便でより高速なアルゴリズムを適用したサブルーチンを開発した。その結果、128ノード使用の場合、約10倍のパフォーマンスを得た。結果と共に本アルゴリズムの特徴、実行条件、拡張性などについて報告する。
松山 雄次*
JAERI-Data/Code 96-006, 49 Pages, 1996/03
JAERI-Data-Code-96-006.pdf:1.51MB
ベクトル計算機用に最適化された等方乱流数値シミュレーション・コード(trans5)を題材にして、並列計算機Paragon XP/S、ベクトル並列計算機VPP500、および日本原子力研究所で開発されたベクトル並列計算機Monte-4での並列化解析ツール、並列化手法、並列最適化環境について検討した。アーキテクチャの異なるこれらの並列計算機における、高速フーリエ変換の並列最適化の効果についても報告する。
折居 茂夫*
HPC-58-5, 0, p.27 - 32, 1995/10
科学技術分野の高速数値シミュレーションを並列計算機で行う場合、シミュレーションの問題の性質、規模、計算機スキーム、アルゴリズム、プログラミング方法が、スケーラビリティに影響を与える。並列計算がシミュレーションプログラム中の並列性を利用するためである。更に、並列計算機のアーキテクチャ、性能仕様、言語等が並列計算機特有のオーバーヘッドを生み、並列性と密接に関係し、スケーラビリティの検討を困難にしている。本研究の目標は、スケーラビリティに影響を与えるパラメータを特定し、それらのパラメータを用いて並列処理時間のモデルを作り、測定と組み合せて、数値シミュレーションプログラムのスケーラビリティ検討方法を確立することである。本論文では、この方法を示し、妥当性を検討するため、例題にコレスキー法を用い、測定をVPP500、Paragonで行った。